Selected cases
A development map of water sports in Russia
An interactive analytics dashboard for the leadership of the Russian Water Sports Federation: from scattered Excel files to a single data-driven decision system.
Problem
Data on athletes, coaches, venues and results was stored across dozens of separate files and systems. Preparing a single analytics report took weeks of manual work. Leadership had no holistic view of the industry.
Solution
- Designed a relational DB (15+ tables, PostgreSQL) to unify all sources
- Geocoding — placed 3,600+ pools across Russia on an interactive map
- A composite index of regions from 124 absolute and 60 aggregated metrics
- Dashboard with regional rankings, heatmaps and filters
- Index system: infrastructure availability, staffing, participation
Result
Leadership got a decision-making tool: where infrastructure is overloaded, where it's underused, which regions are drivers. The ability to model the effect of investments.
Open the interactive map →
in db
sources
on map
A world map of swimming development
From a Russia dashboard to the global picture: an interactive world map that ranks 198 countries by a Swimming-Education Development Index (SDI), built on deep research of official sources.
Problem
There was no single, comparable picture of how countries develop mass swimming education and water safety. The data was scattered across national federations, ministries and methodology documents in dozens of languages.
Solution
- Designed the SDI index — 8 weighted criteria (0–5 scale, weights sum to 100) with a transparent formula
- Deep-research profiles for 198 countries from official sources: federations, ministries, statistics, methodologies
- Interactive D3 + TopoJSON world map: country search, tooltips, side panel and colour legend
- A drill-down page per country plus an open, documented scoring methodology
Result
A single tool to compare countries, separate leaders from laggards and ground decisions in transparent, reproducible scoring.
Open the world map →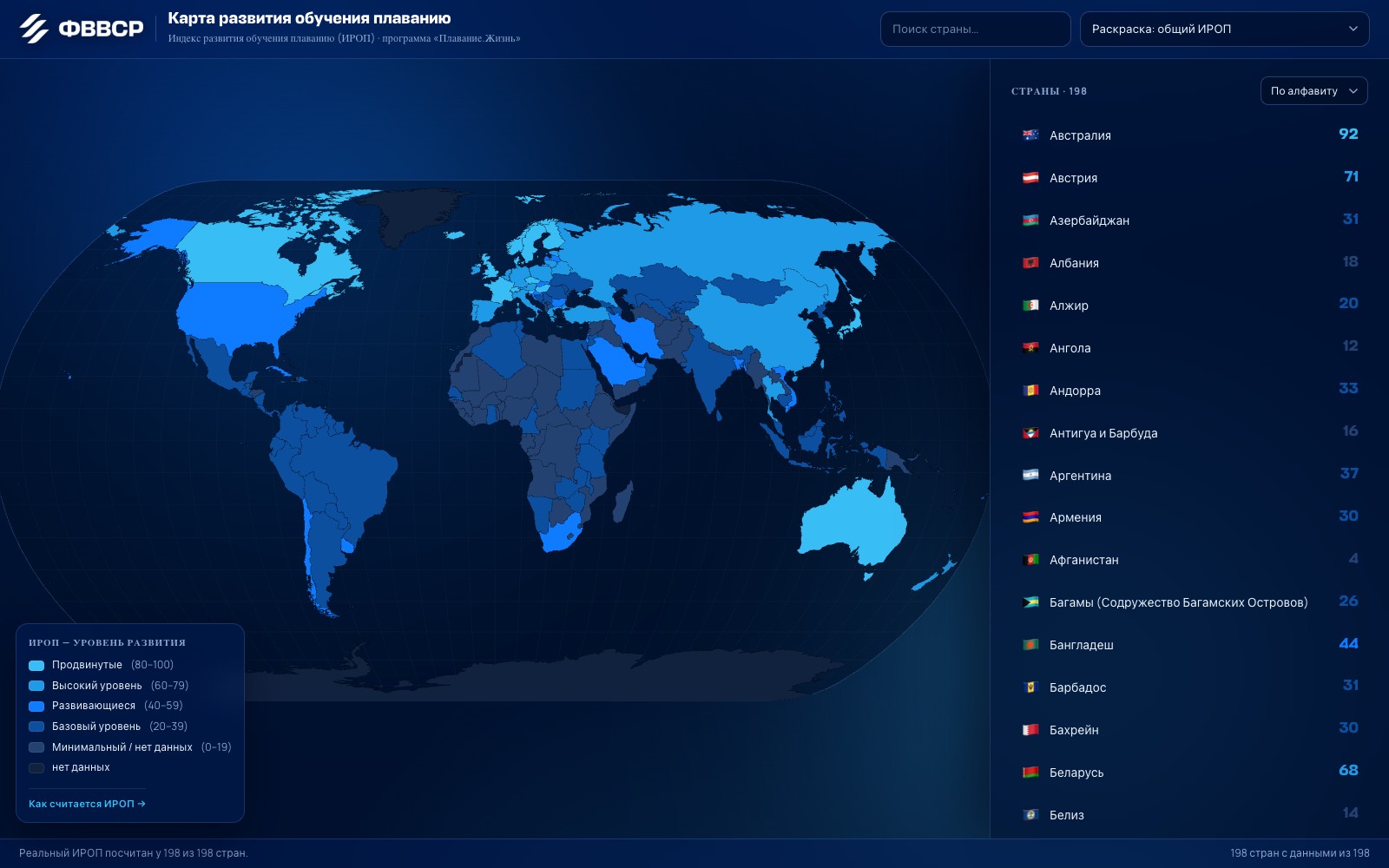
indexed
criteria
scale
Predictive model: who wins a medal?
A model that estimates each swimmer's medal chances from their competition history and result dynamics.
Problem
The federation funds the training of hundreds of athletes, but the budget is limited. Coaches pick candidates intuitively — subjectively and without common criteria.
Solution
- Compared four ML algorithms and chose the best by cross-validation (LightGBM)
- Tuned hyperparameters over 40 iterations (RandomizedSearchCV)
- Identified 8 key factors out of 13 via SHAP feature importance
- Checked class imbalance effect (SMOTE/SMOTENC) — the ceiling is set by data quality
Result
The model predicts a medalist with 91.6% accuracy. Five top factors: current level, peer ranking, progress rate, peak progression, consistency. Every prediction comes with an explanation.

accuracy
factors
compared
Analysing athlete technique from video
A computer-vision system that builds a digital skeleton of an athlete from video, measures joint angles and detects movement asymmetries.
Problem
A coach judges technique by eye — but misses micro-asymmetries that reduce efficiency and raise injury risk. Objective numbers are needed: angles, ranges, side balance.
Solution
- 17 key body points in every frame (YOLOv8 / MediaPipe)
- Angles for each joint, broken down by movement phase
- Automatic left/right comparison — flags asymmetries
- Export to a report with charts to track progress between sessions
Result
Coaches got objective metrics instead of subjective judgement. Athletes correct movements faster and lower injury risk thanks to early imbalance diagnosis.

points
charts
at once
Blood cell detection on microscope images
A neural network that finds and classifies red cells, white cells and platelets on blood-smear images — instantly and without a lab technician.
Problem
Lab technicians count blood cells by hand under a microscope — slow, tiring and error-prone. One image takes minutes, and there are dozens a day.
Solution
- Faster R-CNN (ResNet50-FPN v2), fine-tuned on blood-smear images
- Three classes in one pass: red cells, white cells, platelets
- Transfer learning — adapted in 10 epochs from ImageNet weights
- Each cell boxed with class and confidence
Result
The model confidently detects cells at 0.9+ confidence. One image — in a second instead of minutes of manual counting. A ready base for integration into lab systems.

types
confidence
image
AI automation of business processes
n8n workflows that replace routine: they ingest documents, extract data, draft replies, update databases and dispatch results — with no human in the loop.
Problem
Teams spend hours on repetitive tasks: parsing documents, moving data between systems, drafting standard replies. Each is simple, but there are hundreds.
What's automated
- Inbound document processing: file → AI extracts fields → DB + CRM
- AI assistants with access to a knowledge base (RAG)
- ETL pipelines: APIs/tables/files → cleaning → warehouse
- Document generation from a template + data in seconds
How it works
Each scenario is a visual n8n pipeline: a trigger (webhook, schedule, file) starts a chain of steps, AI processes the data, and the result goes to the right system. 24/7, no code.
in prod
humans
for the user
An agentic pipeline for fund reports
One "Go!" turns 1000+ source documents (~1.5 GB of scans, contracts and estimates) into a fund-ready, financially-audited DOCX — orchestrated by Claude across deterministic Python and a fleet of parallel sub-agents.
Problem
Official grant reports demand a DOCX with a line-by-line financial audit, assembled from gigabytes of messy scans, contracts, payment orders and estimates. By hand it's days of tedious, error-prone work.
Solution
- Claude (Opus, 1M context) orchestrates the run; Python scripts do the deterministic part — indexing, extraction, DOCX assembly, financial audit
- 6 parallel OCR sub-agents read scans, contracts and payment orders; 3 more parse the finances and write the narrative sections
- Confidential financial and personal data is processed by local, on-device models — nothing sensitive ever leaves the machine
- A document-linking graph and triangulated audit reconcile every figure against limits and primary documents
- Per-row Word comments, an auto "remarks to check" doc and a clean fund-ready copy — then a mandatory self-review pass
Result
~1.5 GB of source materials → an audited, fund-ready report in a single run, every line cross-checked and commented. Days of manual work collapse into minutes.

sub-agents
per report
«Go!»
A closed-loop app for athlete health data
A clinical app for sports medicine: it parses lab reports into structured markers, tracks trends against a reference-value catalog, and exports PDF/XLSX — behind role-based access and a full audit trail. Special-category medical data never leaves the closed loop.
Problem
Athletes' lab results — special-category personal data — were scattered across PDFs from different labs. Doctors needed trends over time in one place, but cloud services are a non-starter for sensitive medical data.
Solution
- Parses lab-report PDFs / XLSX from many labs into structured markers (athlete → report → test)
- Trends over time per marker, normalized against a reference-value catalog; dashboards and PDF/XLSX export
- Role-based access (admin / medic / viewer) with per-record scoping, brute-force protection and a full audit log of every action
- Closed loop by design: runs on-prem / behind a corporate VPN, isolated from the public internet; encrypted off-box backups
- A companion smartphone app for access on the go
Result
Doctors get longitudinal trends and instant reports; the organization keeps full control — medical data stays inside the perimeter, every access is logged, and nothing goes to the cloud.

structured
roles
the loop